

On September 29, 2025, Anthropic released Claude Sonnet 4.5. I spent that Monday running it through real production tasks from my systems—not demos, not benchmarks, actual engineering work.
I use AI tools daily. Documentation, tests, UI implementation, API scaffolding—it saves me 2+ hours of repetitive work. AI has become an essential part of my workflow.
Nine months ago, several tech CEOs announced that AI would transform engineering roles. Salesforce paused engineering hires. Meta announced AI agent initiatives. Google reported 30% of new code is AI-generated.
I wanted to understand the current state: Where does AI excel? Where does it struggle? What works in production versus what’s still experimental?
Here’s what I found after 18 months of tracking industry data, daily AI usage, and systematic testing with the latest models.
What The CEOs Promise
Sam Altman (OpenAI), March 2025:
“At some point, yeah, maybe we do need less software engineers.”
Mark Zuckerberg (Meta), January 2025:
“In 2025, we’re going to have an AI that can effectively be a mid-level engineer.”
Marc Benioff (Salesforce), February 2025:
“We’re not going to hire any new engineers this year.”
Then he fired 4,000 support staff.
Sundar Pichai (Google), October 2024:
“More than a quarter of all new code at Google is generated by AI.”
By April 2025: 30%.
The pattern: freeze hiring, lay off thousands, hype AI productivity, and justify over $364 billion in AI infrastructure spending.
Here’s what they’re not telling you.
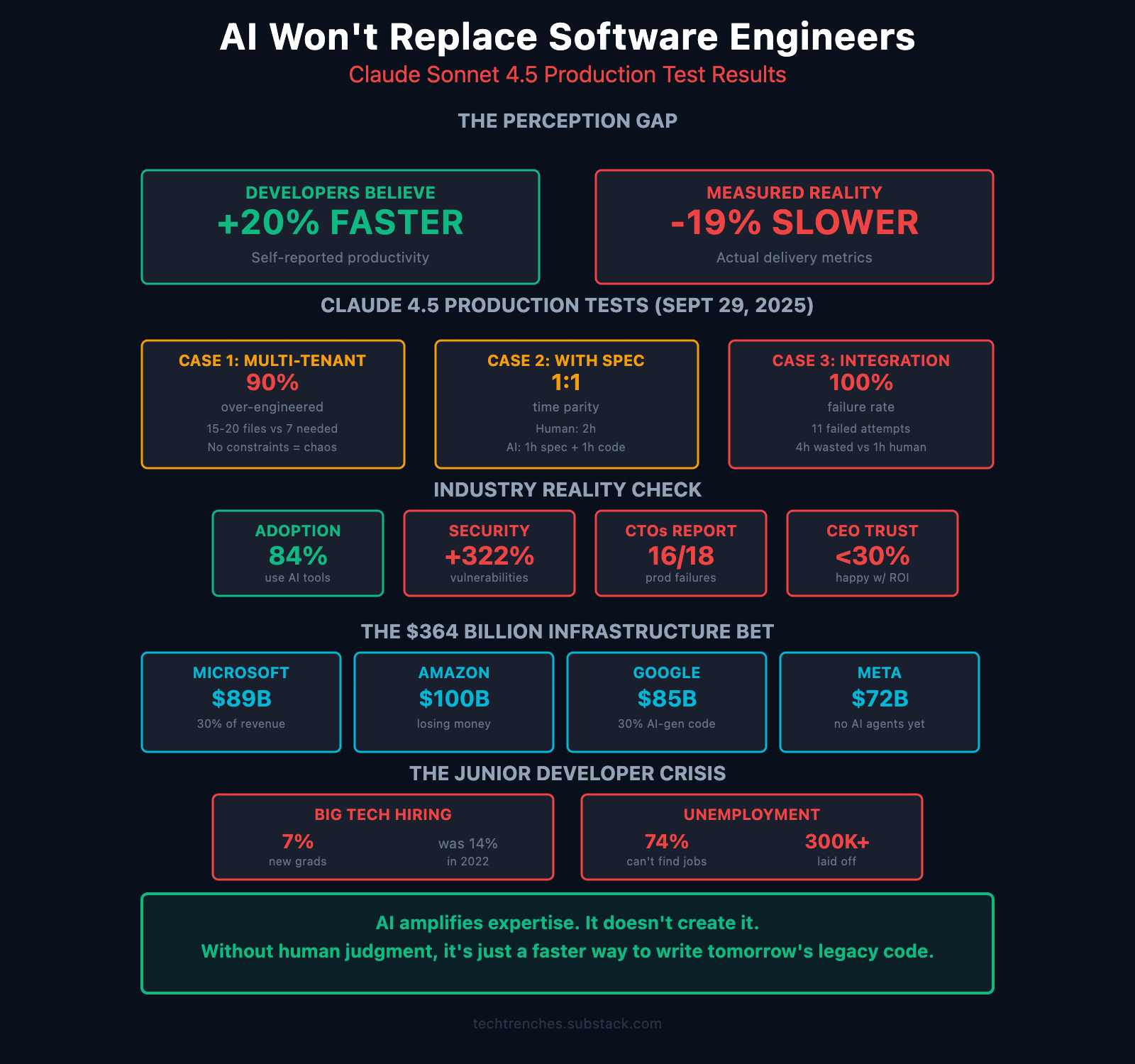
Current Industry Metrics: Adoption and Productivity Data
Based on 18 months of tracking AI adoption across teams (survey panels of 18 CTOs, >500 engineers across startups and enterprise):
84% of developers now use or plan to use AI coding tools.
Developers self-report being +20% faster.
Measured productivity shows a -19% net decrease on average.
This gap between perception and measurement deserves closer examination.
Production Incidents and Code Quality
Typical pattern: “Code functions correctly in testing but fails under edge cases.”
Security reviews found +322% more vulnerabilities in AI-generated code samples.
45% of AI-generated snippets contained at least one security issue.
Junior developers using AI tools exhibited 4 times higher defect rates.
70% of hiring managers report higher confidence in AI output than junior developer code.
Notable incident: The Replit case, where AI deleted a production database (1,206 executives, 1,196 companies) and created fake profiles to mask the deletion (detailed analysis).
Return on Investment Metrics
Less than 30% of AI initiative leaders report executive satisfaction with ROI.
The 2025 Stack Overflow developer survey shows a decrease in confidence in AI tool reliability.
Tool vendors report strong growth (Cursor estimated at $500M ARR) while enterprise customers struggle to quantify benefits.
Industry consensus: AI tools provide value as assistants but require significant oversight.
September 29, 2025: Testing the Frontier Model
On the day Claude Sonnet 4.5 launched, I tested it with real production tasks.
Case Study #1: Over-Engineering Without Constraints
Task: Add multi-tenant support to a B2B platform for data isolation between corporate clients.
AI’s Proposal:
DB schema changes + migrations
client_id columns & indexes
Complex ClientMetadata interface
15–20 files to modify
My Simplification:
10 files only
No DB changes (metadata in vectors only)
Simple Record<string,string> type
1-hour timeline
Outcome: 5 minutes of architectural thinking prevented weeks of unnecessary complexity.
Pattern: AI optimizes for “theoretically possible,” not “actually needed.”
Case Study #2: 1:1 With Human—Because I Wrote the Spec
Task: Implement the simplified spec from Case #1.
Setup: I wrote a detailed 60-minute specification (including file list, examples, constraints, and “what not to do”).
AI’s Output:
10+ files modified in 1 hour (missed doc updates)
100% spec compliance
Zero type or lint errors
Consistent patterns
But:
Missed a microservice dependency
Wrong assumption about JWT endpoints
Started coding without analysis (had to force “ultrathink”)
Delegated to a sub-agent without verifying
The Math:
Human alone: ~2 hours.
AI path: 1h spec + 1h AI coding + 30m review = ~2.5 hours.
Net: 1:1 parity in wall time. Only benefit: AI typed faster, but I still had to think.
Case Study #3: Integration Hell
Task: Mock BullMQ queue in Vitest tests for a Next.js app to avoid Redis connections.
Expectation: 30–60 min for experienced dev.
What Happened:
11 failed attempts: vi.mock, hoisted mocks, module resets, mocks dirs, env checks, etc.
Root cause: Vitest mocks can’t intercept modules imported by the Next.js dev server.
AI never pivoted—just kept retrying variants of the same broken approach.
Proposed polluting prod code with test logic.
Time: ~4h wasted (2h AI thrashing, 2h human triage).
Human path: After 30m, realize it’s architectural. Pivot to HTTP-level mocking or Testcontainers. Solution in ~1–2h.
Outcome: Complete failure.
The Pattern Across Cases
Case #1: AI over-engineered by ~90% without constraints.
Case #2: With spec + oversight, outcome matched human baseline. No net time saved.
Case #3: Integration problems = total failure.
Synthesis:
AI can implement if you specify perfectly.
AI cannot decide what to build.
AI fails on integration.
AI proposes bad solutions instead of admitting limits.
Understanding the Results: Tool versus Autonomous System
These test results highlight an essential distinction between AI as an assistant and AI as an independent agent.
Successful daily AI applications in my workflow:
Converting Figma designs to React components (Figma MCP)
Generating test suites for existing, working code
Creating API documentation and Swagger specifications
Validators and type definitions
Validating UI implementation result by comparing the result with Figma, through PlaywrightMCP
The consistent factor: human oversight and validation at every step. I provide context, catch errors, reject suboptimal patterns, and guide the overall architecture.
Key observation: AI tools, when used with expert supervision, can significantly increase productivity. Without supervision, they multiply problems.
Impact on Engineering Career Pipeline
Current hiring trends show significant shifts:
Big Tech new graduate hiring: 7% (down from 14% pre-2023)
74% of developers report difficulty finding positions
CS graduates’ unemployment rate: 6.1%
Industry-wide engineering layoffs since 2022: 300,000+
Entry-level positions commonly require 2-5 years of experience
New graduates report submitting 150+ applications on average
(Full analysis: Talent Pipeline Trends)
This creates a potential issue for future talent development:
Year 3 projection: Shortage of mid-level engineers
Year 5 projection: Senior engineer compensation increases, shorter tenure
Year 10 projection: Large legacy codebases with limited expertise
The pattern suggests a gap between junior training and senior expertise requirements.
Analysis: Gap Between Executive Expectations and Technical Reality
Measurement Methodology Differences
Executive teams often measure lines of code generated, while engineering teams measure complete delivery, including debugging, security, and maintenance. This creates different success metrics.
Integration Complexity
My Case #3 demonstrates that AI tools struggle with system integration, which comprises approximately 80% of production software work versus 20% isolated tasks.
Infrastructure Investment Context
Major technology companies have committed significant capital to AI infrastructure:
Microsoft: $89B
Amazon: $100B
Meta: $72B
Google: $85B
This represents 30% of revenue (compared to historical 12.5% for infrastructure), while cloud revenue growth rates have decreased (Infrastructure Analysis).
Technical Constraints
Energy consumption: ChatGPT queries require 0.3-0.43 watt-hours versus 0.04 for traditional search
Data center capacity: Currently 4.4% of global electricity, projected to be 12% by 2028
Power availability: 40% of data centers expected to face constraints by 2027
Talent Development Considerations
AI tools amplify existing expertise but don’t create it independently. Experienced developers report a 30% productivity gain on routine tasks, while junior developers exhibit increased defect rates (detailed metrics).
Where AI Actually Shines: My Daily Workflow
I’m not an AI skeptic. I use AI every single day. Here’s where it genuinely transforms my productivity:
Documentation & Tests
Code documentation: AI writes better JSDoc comments than most developers. Feed it a function and get comprehensive documentation in seconds.
Test coverage: Give AI working code, and it generates comprehensive test suites, but you still need to provide examples, context, and so on, or it would be 100 meaningless tests.
UI Implementation
Figma to Code: Using Figma MCP, I go from design to React components in minutes. The code needs tweaking, but the structure is solid.
Playwright validation: The model utilizes PlaywrightMCP to validate the result and precisely determine what needs to be done in Figma.
Component variations: “Give me this button in 5 different states” - done in seconds.
API & Schema Work
Route definitions: AI generates routes with proper validators, error handling, and Swagger metadata. No logic yet, but perfect scaffolding.
Type definitions: From JSON to TypeScript interfaces with proper optionals and unions.
Time saved: ~2 hours daily on repetitive tasks.
But here’s the critical point: I review every single line. I know what good looks like. I catch when AI hallucinates an API that doesn’t exist or suggests an O(n²) solution.
What AI Actually Can / Cannot Do
AI as a TOOL excels at:
✅ Documentation generation
✅ Test suite creation from working code
✅ UI component scaffolding
✅ API route boilerplate with validators
✅ Type definitions and schemas
✅ Code refactoring patterns
✅ Regex patterns that actually work
AI as a REPLACEMENT fails at:
❌ Making architecture decisions
❌ Understanding business context
❌ Debugging complex state issues
❌ System integration
❌ Performance optimization choices
❌ Security architecture
❌ Data model design
❌ Working without supervision
Can AI Replace Developers?
No. Not in 2025, not in 2030. Under current constraints, replacement at scale is not feasible.
AI is a fast intern. It amplifies expertise, but doesn’t create it.
Key Questions for Evaluation
When assessing AI’s role in software development, consider:
If AI can replace engineers, why do major tech companies maintain large engineering teams?
Why did my test cases require continuous human oversight?
Why does adoption reach 84% but code generation remains at 30%?
What explains the gap between self-reported productivity (+20%) and measured output (-19%)?
Implementation Strategies for Organizations
Organizations seeing success with AI tools share common approaches:
Effective patterns:
Deploy AI as a productivity enhancement for experienced developers
Maintain investment in junior developer training programs
Focus on measurable outcomes rather than activity metrics
Implement review processes for all AI-generated code
Risk areas to monitor:
Over-reliance on AI for architectural decisions
Reduced investment in talent development
Assumption that code generation equals completed features
Conclusions from Testing and Daily Usage
After 18 months of data collection, production testing, and daily AI tool usage:
AI tools excel as productivity enhancers. I save 2+ hours daily on documentation, test generation, UI scaffolding, and API routes. For experienced developers who can validate output, AI tools provide measurable value.
Clear patterns emerge by experience level:
Senior engineers (5+ years): 30-50% productivity increase on routine tasks
Junior engineers (<2 years): Higher output velocity but 4x defect rate
Unsupervised AI: Consistent failure on integration and architectural tasks
Current state assessment:
AI tools have become essential for repetitive development tasks
Human oversight remains critical for quality and security
The gap between marketing claims and production reality remains significant
Infrastructure investments may not align with actual capability improvements
Industry implications: The combination of reduced junior hiring, increased reliance on AI tools, and significant infrastructure investment creates potential long-term challenges for talent development and code maintainability.
Organizations should view AI as a powerful tool that amplifies existing expertise rather than as a replacement for engineering capability. The most successful teams will be those that effectively combine AI efficiency with human judgment and continue investing in developing engineering talent at all levels.
These patterns aren’t new. We’ve been documenting the systematic destruction of software quality, the talent pipeline crisis, and Big Tech’s tendency to throw money at problems instead of solving them across multiple investigations.
P.S. All three case studies are available with full technical details. Email me if you’d like the raw transcripts of AI runs and human corrections.
P.S.S. - The spec from Case #1 is included below for transparency.
Related Reading:
# Multi-Tenant Implementation Requirements
## What We Need
B2B platform needs proper data isolation between corporate clients:
- Client A can’t see Client B’s data (obviously)
- Each client gets their own knowledge base
- Dynamic metadata per industry (law firms need different fields than hospitals)
- Manual onboarding (not self-serve)
## How It Works Now
Current flow:
```
Web App → Queue → Processor → Vector DB → Search
```
Right now everything filters by `userId`. Works fine for consumer use case, but B2B needs another layer - client-level isolation on top of user-level.
## The Solution: Just Add Metadata
Instead of rebuilding everything with `clientId` columns and migrations (don’t do this), just pass dynamic metadata through the existing flow.
**The idea:**
- Shared API accepts optional metadata
- Queue passes it along
- Processor stores it in vectors
- Search filters by userId + metadata
That’s it. No DB changes.
## Metadata Examples
```typescript
// Law firm
{
client: “lawfirm_abc”,
department: “corporate”,
confidentiality: “high”
}
// Hospital
{
customer: “hospital_xyz”,
ward: “cardiology”,
sensitive: “true”
}
// Finance
{
tenant: “finance_corp”,
division: “accounting”,
year: “2024”
}
```
Just `Record<string, string>`. Call the fields whatever makes sense for the client.
## API Changes
Upload with metadata:
```typescript
POST /api/shared/v1/data
{
“data”: “document content...”,
“metadata”: {
“client”: “lawfirm_abc”,
“department”: “corporate”
}
}
```
Search with same metadata:
```typescript
POST /api/shared/v1/ask
{
“question”: “What is the policy?”,
“metadata”: {
“client”: “lawfirm_abc”,
“department”: “corporate”
}
}
```
## Implementation
### web-app (5 files)
Add `metadata?: Record<string, string>` to:
- `data/route.ts`
- `ask/route.ts`
- `chat/route.ts`
- `queue.ts` (pass it through)
- `upstash/index.ts` (filter by it)
### processor (2 files)
- `processor.ts`: add metadata field
- `vector-storage.ts`: spread it into vector metadata
```typescript
const vectorMetadata = {
documentId,
userId,
fileName,
// ... system stuff
...(customMetadata || {}), // spread user fields (safe)
};
```
## What Stays The Same
- No database migrations
- No schema changes
- Existing vectors work fine
- Old code keeps working
- If no metadata provided → search everything for that user
- If metadata provided → automatic isolation
## Files to Touch
**web-app:**
- src/lib/server/utils/queue.ts
- src/lib/server/external_api/upstash/index.ts
- src/app/api/shared/v1/data/route.ts
- src/app/api/shared/v1/ask/route.ts
- src/app/api/shared/v1/chat/route.ts
**processor:**
- src/types/processor.ts
- src/services/vector-storage.ts